Orion 2: Frontier Visual Agents with Code Execution

We are excited to announce Orion 2: our most capable visual agent, now with code execution. Since our Orion 1 launch in November last year, our customers have run hundreds of thousands of requests spanning millions of tool-calls in production every month. Serving at this scale taught us that the bottleneck in production visual agents isn't just accurate perception – it's reliable orchestration.
Orion 2 generates and executes computer-vision code on the fly, expanding capabilities well beyond Orion 1 while being significantly faster, cheaper, and more reliable. Try it now at chat.vlm.run, every example in this post is a live chat thread you can inspect and re-run.
Visual Intelligence, now with Code-Mode
Complex computer vision tasks are inherently compositional: detect, crop, draw, measure, reason. Most vision agents are restricted to a predefined tool surface and a sequential tool-calling loop. With Orion 2, we combine deterministic tool-calling with dynamic code generation – the best of both worlds.
Code as the orchestration substrate (aka code-mode) has several properties that matter in production:
- Reusable: generated programs are artifacts; scripts can be saved, versioned, and re-run on new inputs without re-invoking the LLM agent.
- Inspectable: the executed code is something you can read, debug, diff, and verify; critical for our customers in regulated industries.
- Composable: loops, conditionals, fan-out, and parallel tool calls live in a single program instead of N model round-trips.
- Deterministic: computation (counting, measuring, normalizing, geometry) runs in code, not in the model's head; eliminating an entire class of numeric hallucinations.
Architecture: Code as the Agent Harness
Orion 2 is a visual agent harness: a planner and a code runtime wrapped around a vision-language model. At its core is a custom visual DSL and runtime we built to expose every tool we introduced with Orion 1 – detection, OCR, segmentation, cropping, image generation, and more – as native primitives the model can compose in code. Most notably, the entire Orion 1 tool surface is now fully programmable and deterministic.
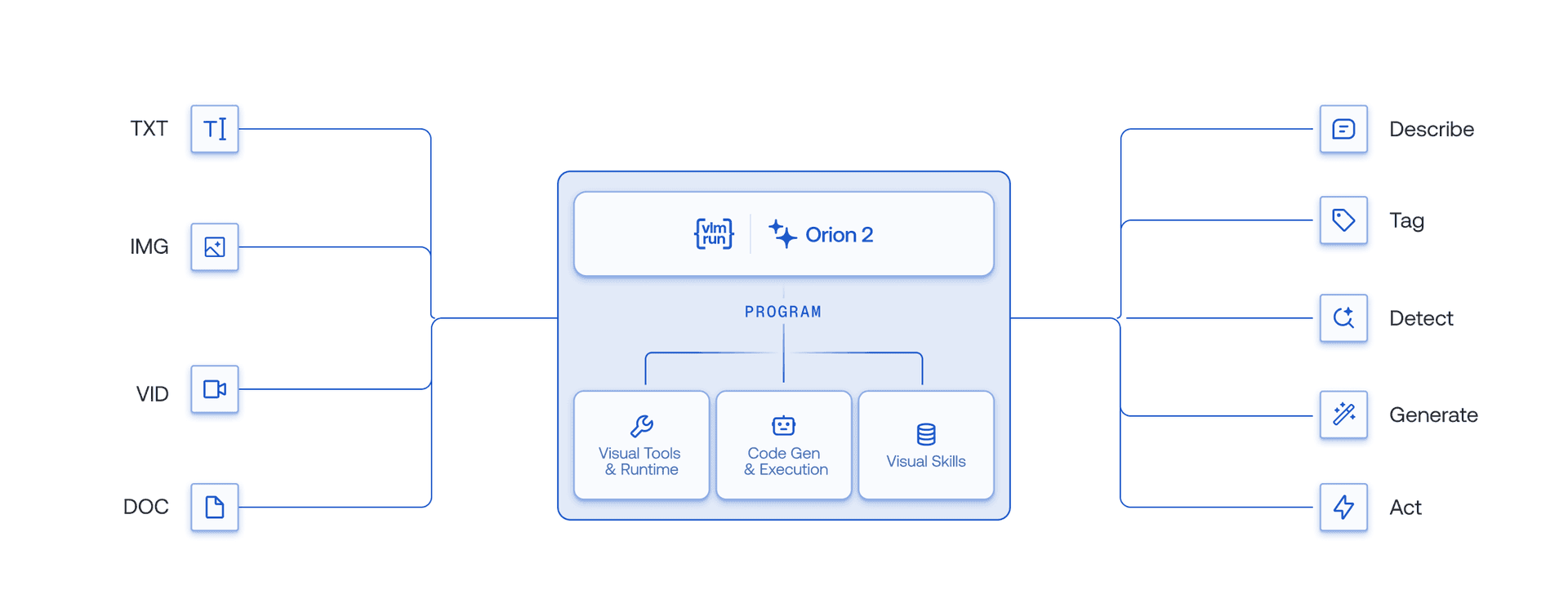
Here is how a new request is handled in Orion 2:
- Prompt → Spec: An ambiguous request is compiled into an exact, executable program – written in our visual DSL, which reads like idiomatic Python.
- Execution: The program runs in a sandboxed runtime with async-native parallelism: independent operations dispatch concurrently via asyncio, with no per-step model round-trips. The runtime ships with OpenCV for classical computer vision and the
vlmrunpackage, which exposes the full Orion tool surface – detection, OCR, segmentation, image generation – as importable primitives. - Self-correction: Execution results return to the harness, which repairs and re-executes until the program runs to completion. Each turn also yields a (program, trace, outcome) record – fully verifiable supervision for our continual-learning flywheel.
That record is also the groundwork for what comes next: close the loop with a visual judge, a harness that can score its own outputs, prefer better programs over worse ones, and improve recursively with every workload it serves. More on that soon.
Orion 1 vs. Orion 2
The difference is easiest to see on a concrete task: the virtual try-on from the examples below, which composes detection, cropping, and image generation across two input images.
Orion 1's orchestration is lazy and interactive: one tool call, one LLM round-trip, repeat. Five visual operations means five round-trips, and every intermediate result (bounding boxes included) passes through the model's context before the next step:
Orion 1: Sequential Tool-Call Illustration
# Tools are called sequentially, with LLM reasoning at each step
boxes = tool_call("detect", image, target="person") # call 1
person = tool_call("crop", image, xywh=[0.22, 0.35, 0.04, 0.15]) # call 2
garment = tool_call("detect", dress_img, target="garment") # call 3
garment = tool_call("crop", dress_img, xywh=[0.33, 0.41, 0.05, 0.13]) # call 4
result = tool_call("generate", person, garment) # call 5
# ...the model parses every intermediate output before deciding the next tool.Notice the coordinates in calls 2 and 4: the LLM reads them out of the detection results and calls them into the next tool call. Every hop like that costs a round-trip of latency and is a chance to transcribe something wrong.
Orion 2: Efficient Code-Mode Execution
Orion 2's orchestration is code. The model writes one program up front; intermediate results flow through variables instead of the model's context, independent operations run in parallel, and the whole workflow executes end-to-end before returning:
# Tools can be called efficiently via native async python ops
import asyncio
async def process(ctx, person_image, dress_img):
vlmrun = ctx.import_lib("vlmrun")
def crop(img, d):
bx, by, bw, bh = d["xywh"]; W, H = img.width, img.height
return img.crop(int(by * H), int((by + bh) * H), int(bx * W), int((bx + bw) * W))
# Detect person and garment in parallel, take top crop of each
p_det, g_det = await asyncio.gather(
vlmrun.image.detect(person_image, "person"),
vlmrun.image.detect(dress_img, "garment"),
)
person_crop = crop(person_image, p_det["detections"][0])
garment_crop = crop(dress_img, g_det["detections"][0])
# Composite the try-on and return the composite image
(composite,) = await vlmrun.image.generate(
"virtual try-on", images=[person_crop, garment_crop]
)
return {"composite": composite}When orchestration is code, verifiable correctness and determinism is a property of the program, even if a statistical model generated it.
Under the Hood: Model-Agnostic, Purpose-Built Runtime
Orion 2 is a visual agent harness, not a model. Any multimodal model with strong code generation can drive the planner → execution → self-correction loop: open-weight VLMs like Gemma4-26B-A4B and Qwen3.6-35B-A3B, or frontier models like Gemini 3.5 Flash. Same harness, same runtime, different engine.
The benchmark below runs all three backbones through the identical harness. Each brings different strengths – Gemma4 leads on localization, Gemini 3.5 Flash on segmentation and video – and Orion 2 inherits every improvement in vision-grounded code generation, open or closed, for free.
The default, vlmrun-orion-2:auto, routes each request to the best backbone for the job, so you get the frontier of all three without choosing. Open-weight backbones run on our purpose-built inference runtime: favorable GPU economics at volume, deployable in isolated cloud environments. Pin a fixed backbone through the gateway when compliance or reproducibility demands it.
Examples
See Orion 2 in action in the following chat thread examples and inspect the artifacts.
Virtual try-on
Given an image of a dress and an image of a model, Orion 2 creates a realistic virtual try-on in a single turn. It detects the person and the garment in parallel, crops each subject in-process, generates the composite with one image-generation call, and asks a vision-LLM whether the fit looks natural – composing four distinct visual operations as a single program, with the intermediate crops, composite, and verdict all available as inspectable artifacts. See chat.
Loading chat preview…
Robotics & Physical AI
Orion 2 extracts a representative frame from a robotics video, segments every object in the scene in parallel, and hands off the per-object masks to generate an interactive 3D reconstruction. The frame sampling, fan-out segmentation, and 3D-reconstruction handoff all live in a single program, so the intermediate frame, masks, and reconstruction are produced together in one turn and available as inspectable artifacts. See chat.
Loading chat preview…
Multi-document workflow
Given a multi-page healthcare PDF, Orion 2 splits a batch of healthcare documents into per-page images and classifies each one – claim form, instructions, insurance ID card, medical history, physician referral form etc. It then focuses on the referral form, helping the user localize the patient and physician names, and returns the full structured extraction grounded to the source page – every page split and bounding box available as inspectable artifacts. See chat.
Loading chat preview…
Manipulating Images
Orion 2 manipulates images on-the-fly with native OpenCV – Gaussian blur, Canny edge detection, color pop, and other cv2 compositions are written directly into the script and run in parallel where independent operations can be composed, instead of being constrained to a fixed, pre-defined tool surface. See chat.
Loading chat preview…
Benchmarks
When we launched Orion 1, we showcased a benchmark dataset of 30+ multi-modal, multi-turn tasks involving complex reasoning and agentic actions on images, documents, and videos.
With Orion 2's code-execution capabilities, we expand the benchmark to 250+ multi-turn cases across image, document, audio, video, and multi-file inputs, covering perception, counting, OCR, grounding, and cross-turn reasoning. The hard tier introduces generative tool-use actions – cropping, masking, blurring, redaction, segmentation, keyframe extraction – that exercise Orion 2's code-mode through the VLM Run Chat Completions API.
Although state-of-the-art multimodal models perform well on many vision tasks, they do not cover the full spectrum of visual capabilities and are largely constrained to text-based outputs. Orion extends beyond traditional MLLMs by providing both pixel-level understanding and spatial reasoning capabilities, enabling richer interactions with visual content and more precise grounding in the visual world.
Get started
Try Orion 2 now at chat.vlm.run. Bring your own favorite images, documents, or videos and inspect the programs it writes. When you're ready to build, the same agent is available through the VLM Run Chat Completions API, and our team can help you evaluate it on your production workloads.
Related posts
View all