Blog


Dinesh Reddy
Sudeep Pilai
Feb 16, 2026


Healthcare organizations deal with a constant flood of documents arriving from multiple sources — emails, faxes, scanned forms, and digital uploads. Extracting the right information from these documents quickly and accurately is critical for patient care, yet it remains one of the most labor-intensive tasks in healthcare operations.
Scan.com, a leading platform connecting patients with diagnostic imaging services, faced this challenge head-on. With a high volume of exam requests arriving alongside varied supporting documents and emails, their team needed a way to process everything faster without sacrificing accuracy.
That's when they turned to VLM Run's Orion Agent - a visual AI agent that classifies, extracts, and verifies exam details from documents and emails in a single API call. Scan.com has now been running the Orion Agent in production for months, processing documents at scale with high reliability.
The Problem: Why OCR and Traditional Document Processing Fall Short
Scan.com receives exam requests from a wide network of referring providers. Each request typically arrives as a bundle: a multi-page document (often containing referral forms, clinical notes, and prior exam results) accompanied by an email with additional context and instructions.

Real-world healthcare documents come in every format - patient referral forms, CT scan histories, radiology requests, and handwritten clinical notes. Exam types are circled, checkboxes are hand-marked, and critical details are written in margins. OCR tools only extract text and miss this visual information entirely.
The core challenge was that exam details are inherently visual - they aren't just typed text sitting neatly in fields. In real-world healthcare documents, critical information is conveyed through:
- Hand-marked checkboxes and circled items: Providers select exam types by checking boxes, circling options on pre-printed forms, or marking items with an "X" - information that is invisible to text-based OCR.
- Handwritten annotations and notes: Exam-specific instructions, clinical details, and patient notes are often handwritten in margins or between printed fields.
- Mixed visual formats: A single page might combine typed text, hand-marked selections, stamps, signatures, and freeform annotations - all of which carry meaning that OCR simply cannot capture.
- Emails paired with documents: Critical exam context was often split between the email body and the attached document, requiring staff to mentally combine both sources.
Traditional OCR tools only extract text - they have no understanding of checkmarks, circled items, spatial relationships, or visual context. Adding LLMs on top of OCR doesn't solve this either: if the OCR layer never "saw" the hand-marked checkbox or circled exam type in the first place, no amount of downstream language processing can recover that information. The result is incomplete, unreliable extraction that still requires extensive manual review.
This is fundamentally a visual understanding problem, not a text extraction problem — and it demands a visual AI solution.
The Solution: VLM Run's Orion Visual AI Agent
Scan.com integrated VLM Run's Orion Agent to automate their entire document processing workflow. Unlike OCR-based pipelines, the Orion Agent processes documents as images — seeing the full visual context of every page just as a human would. It processes both the email and the attached document together in a single agent call, extracting and verifying exam details end-to-end. Here's how:
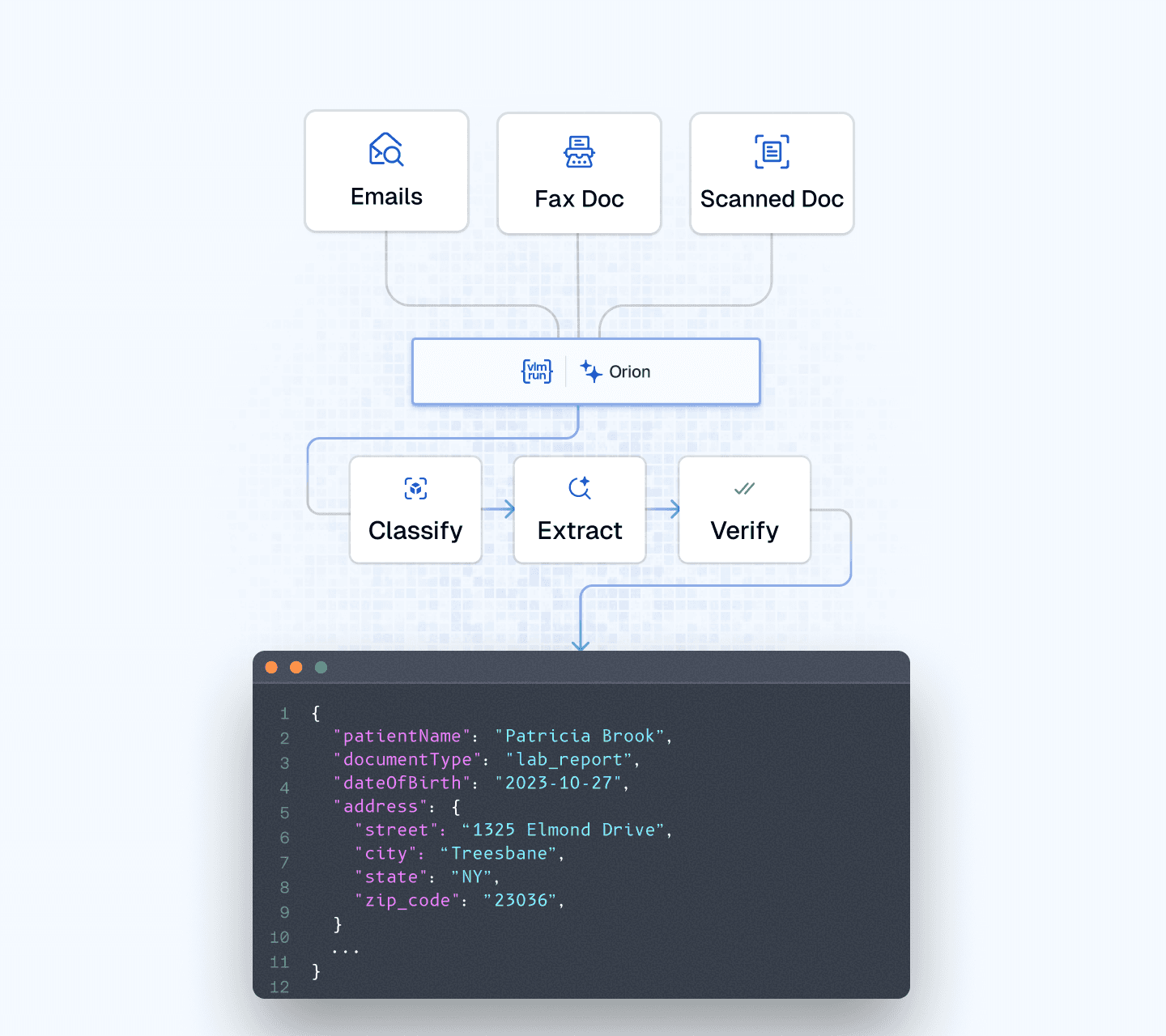
The Orion Agent in action: real healthcare documents — emails, faxes, and patient records — are ingested by VLM Run, which classifies, extracts, and verifies them in a single API call, producing structured, high-confidence JSON results.
1. Intelligent Page Classification
✓ Automatically classifies large, multi-page documents to identify the relevant pages
✓ Filters out noise - only the pages pertaining to the exam request are processed
✓ Handles diverse document formats including faxed, scanned, and digital documents
2. Visual Extraction from Documents and Emails
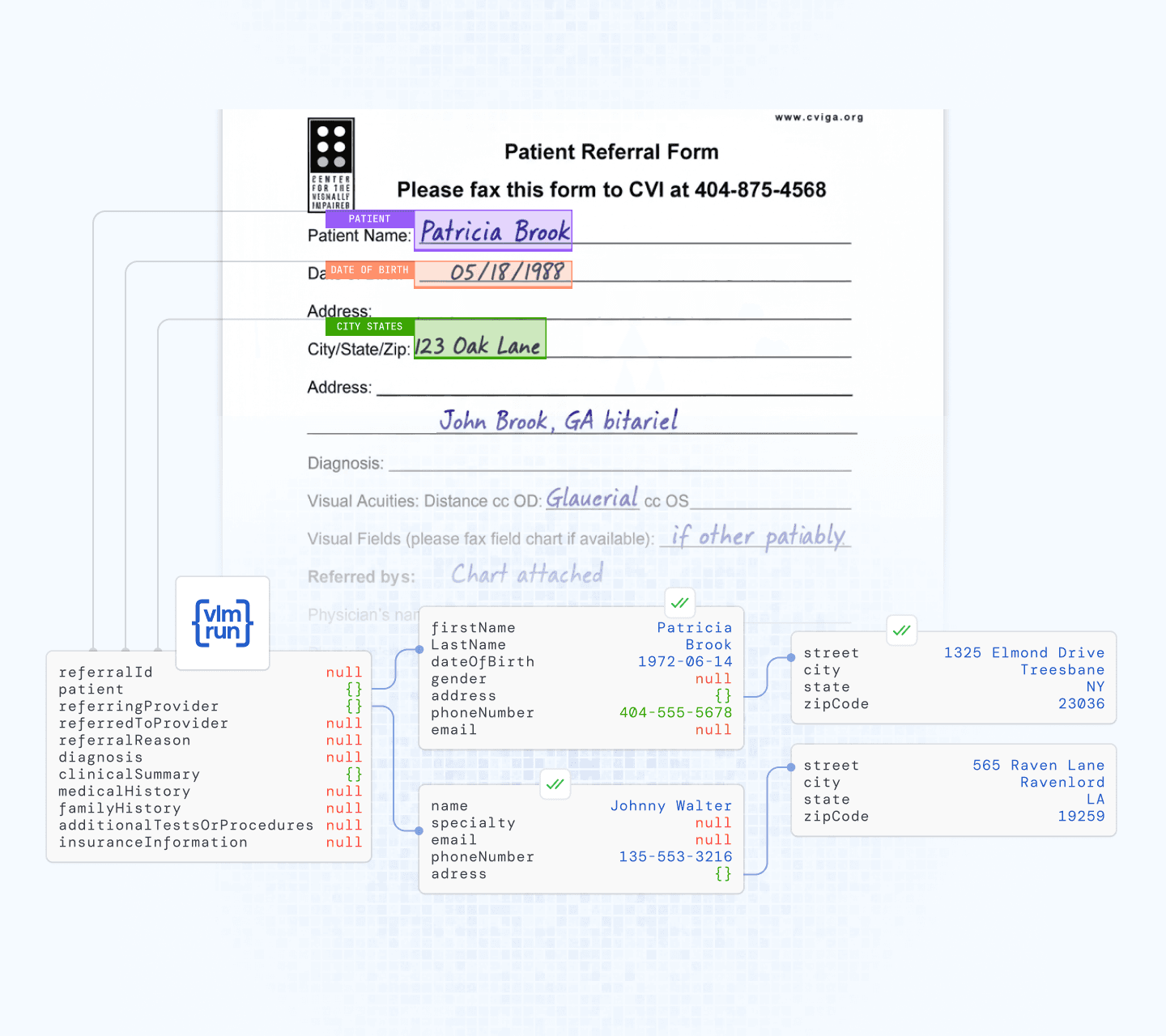
VLM Run extracts structured data directly from handwritten healthcare forms — patient names, dates of birth, addresses, phone numbers, and referring provider details are pulled into structured JSON fields, with each extraction visually grounded to the source document.
✓ Extracts exam details from both the email and the document simultaneously
✓ Sees and interprets hand-marked checkboxes, circled items, handwritten annotations, and typed text - not just OCR-readable characters
✓ Captures the full visual context of each page, understanding spatial relationships between fields, marks, and annotations
✓ Pulls patient information, exam types, clinical notes, and provider details into structured JSON
3. Built-In Visual Verification for High-Confidence Results
✓ Verifies every extraction against the original document rendered as an image — the agent visually confirms what it extracted
✓ Cross-references data between the email and document to ensure consistency
✓ Delivers high-confidence, reliable results in a single API call — no manual QA loop required
The key innovation is that all three steps — classification, extraction, and verification — happen within a single Orion Agent call. Because the agent operates on the visual representation of the document, it captures information that text-based pipelines structurally cannot. This eliminates the need for multiple API calls, complex orchestration logic, or manual review stages.
Results: Faster, More Reliable Exam Processing

Side-by-side comparison of key metrics before and after implementing VLM Run — from slow, error-prone manual QA to fully automated processing with >98% accuracy, reduced engineering effort, and a single unified API.
Here is what a Peaky Yuter, a product manager at Scan.com had to say about how Orion:
"VLM Run's Orion Agent has been a game-changer for our document processing pipeline. What used to require manual cross-referencing between emails and multi-page documents now happens seamlessly in a single call. The built-in verification step gives us the confidence that the extracted data is accurate, which is critical when it directly impacts patient exam scheduling." — Peaky Yuter, Product Manager, Scan.com
A Partnership to Solve a Universal Healthcare Challenge
Working with the Scan.com team on this project highlighted a problem that extends far beyond any single organization. Healthcare documents are inherently visual — exam details are marked, circled, handwritten, and annotated in ways that text-based tools were never designed to handle. The challenge of processing these multi-source documents — emails, faxes, scans, and handwritten forms — is universal across healthcare.
By combining intelligent classification, visual extraction, and built-in verification into a single visual AI agent call, the Orion Agent offers a scalable solution to one of healthcare's most persistent operational bottlenecks.
It was a pleasure collaborating with the Scan.com team to bring this workflow to life, and we're excited to see the impact it will have on patient care and operational efficiency.
Ready to automate your document workflows?
Schedule a demo or contact Sales at sales@vlm.run to learn how VLM Run's Orion Agent can transform your document processing.
Table of contents


