
Fast-Tracking Visual AI in Construction using VLM Run

Data extraction from complex tables in documents presents a significant challenge for businesses across industries. Tables come in countless formats, with varying structures, merged cells, and often embedded in low-quality scans or PDFs that traditional OCR solutions struggle to interpret accurately.
Developers especially in construction face this exact challenge when needing to extract structured data from complex tables in construction plans. Existing solutions that rely on traditional OCR tools and manual parsing scripts require extensive maintenance and time consuming optimization and slow to process.
VLM Run offers a developer-friendly Visual AI solution that quickly addresses even the toughest edge cases where other providers fall short. With a single, unified API, VLM Run transforms unstructured visual content—like complex tables in construction documents—into structured JSON, delivering the accuracy and performance that traditional tools can't match.
Hitting the Wall with Traditional Image Parsing
Before adopting VLM Run, engineering teams encounter significant roadblocks with traditional OCR and document AI-based methods:
☑️ Traditional OCR tools like AWS Textract, GCP Doc AI and even recent AI-based solutions failed to understand table structures and relationships between cells
☑️ Custom parsing scripts required constant updates for each new table format
☑️ Merged cells, nested tables, and poor-quality scans created persistent extraction errors
☑️ Engineering resources were diverted to maintaining complex parsing logic and handling multiple edge cases rather than core product development
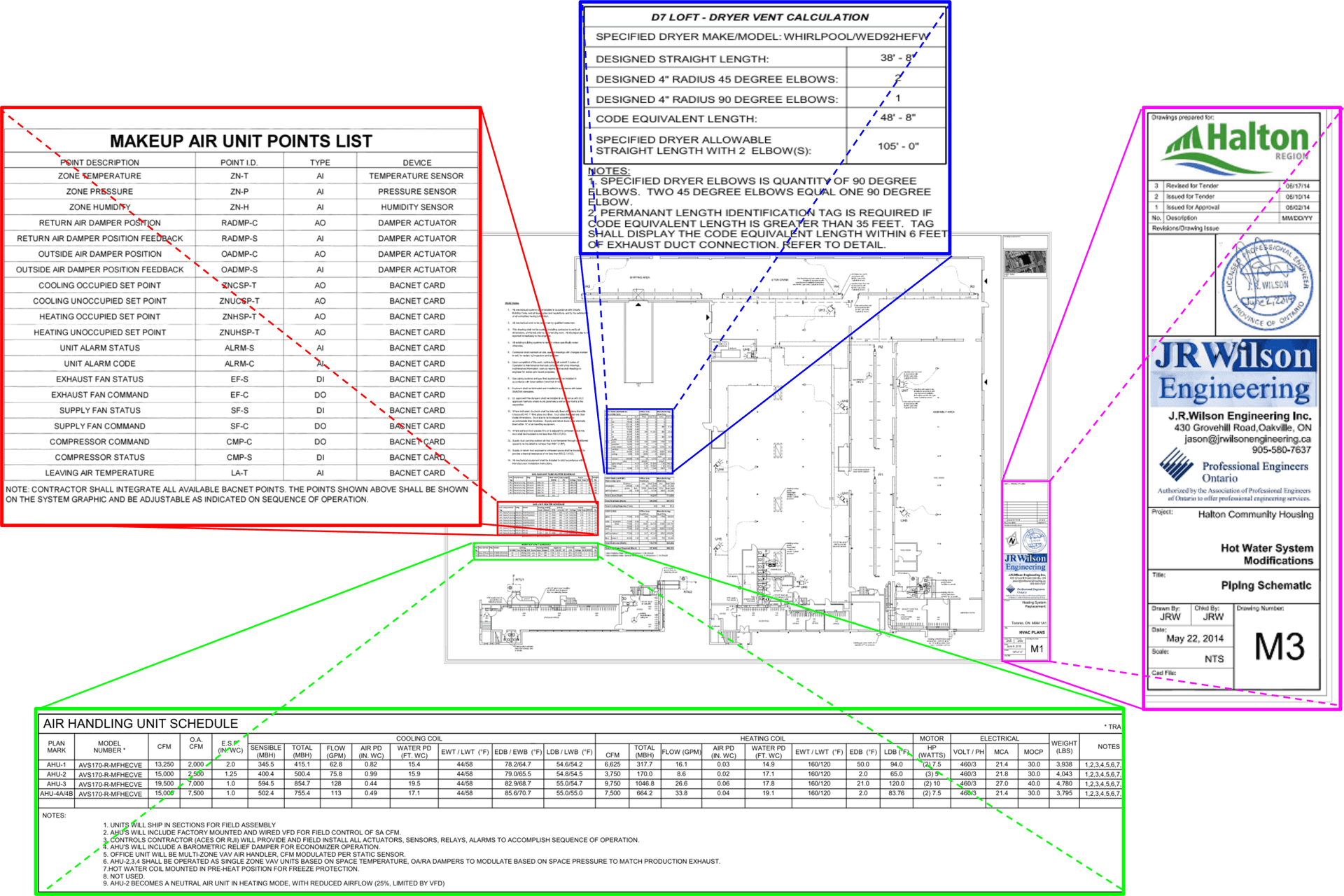
Example of the complex tables needed to process - varying formats, merged cells, and embedded in documents with inconsistent layouts made this a challenging problem for traditional OCR, recent AI-based solutions, and parsing approaches.
We evaluated multiple vendors and solutions—including ChatGPT O1, Azure Doc AI, and newer AI offerings like Gemini 2.5 Pro—but none could guarantee accurate results for their specific use case. Most providers offered generic table extraction that still required heavy post-processing and custom development, falling short on both performance and accuracy. In contrast, we delivered a customizable, fine-tuned solution built specifically for their needs—solving challenges others couldn’t.
Why Construction Teams are Choosing VLM Run
Engineering teams need a solution that can tackle the complexity of table extraction without the traditional overhead. VLM Run provides exactly that—a production-ready Visual AI platform that transforms table parsing operations with a single, unified API and a highly customized approach.

A quick example of VLM Run's Table to JSON API in action -- we render the MARKDOWN to make it easier to visualize the underlying structure of the JSON that the construction company engineers can now use to directly integrate with their platform.
A Superior Table Parsing Solution with Customization
☑️ Custom schema tailored to customer’s exact needs
☑️ Handles messy structures—merged cells, nested relationships, headers, and even multi-page tables
☑️ Works reliably across a variety of formats and document quality
Enterprise-Ready, Out of the Box
☑️ JSON outputs that plug straight into their existing workflows
☑️ Confidence scoring baked in to flag uncertain extractions
☑️ Smart post-processing for each table type
☑️ Automated checks to make sure the data is clean and trustworthy
From Zero to Production in Under 2 Weeks
☑️ Simple REST API with clear docs
☑️ Integration took less than 10 lines of code
☑️ Ready for scale, security, and fine-tuning
☑️ Ongoing support for weird edge cases and new table types
Results comparison to other solutions
When it comes to extracting structured data from documents, accuracy and reliability aren’t optional—they’re essential. As shown in the chart below, our model (vlm-1) leads the field with a 98% accuracy rate, outperforming major players like Azure Doc AI, GPT-4o, and Gemini 2.5 Pro. But it’s not just about precision vlm-1 is also built for scale, consistently handling 32+ concurrent requests without compromising performance. Whether you're processing a handful of documents or deploying at enterprise scale, this model delivers results you can trust.
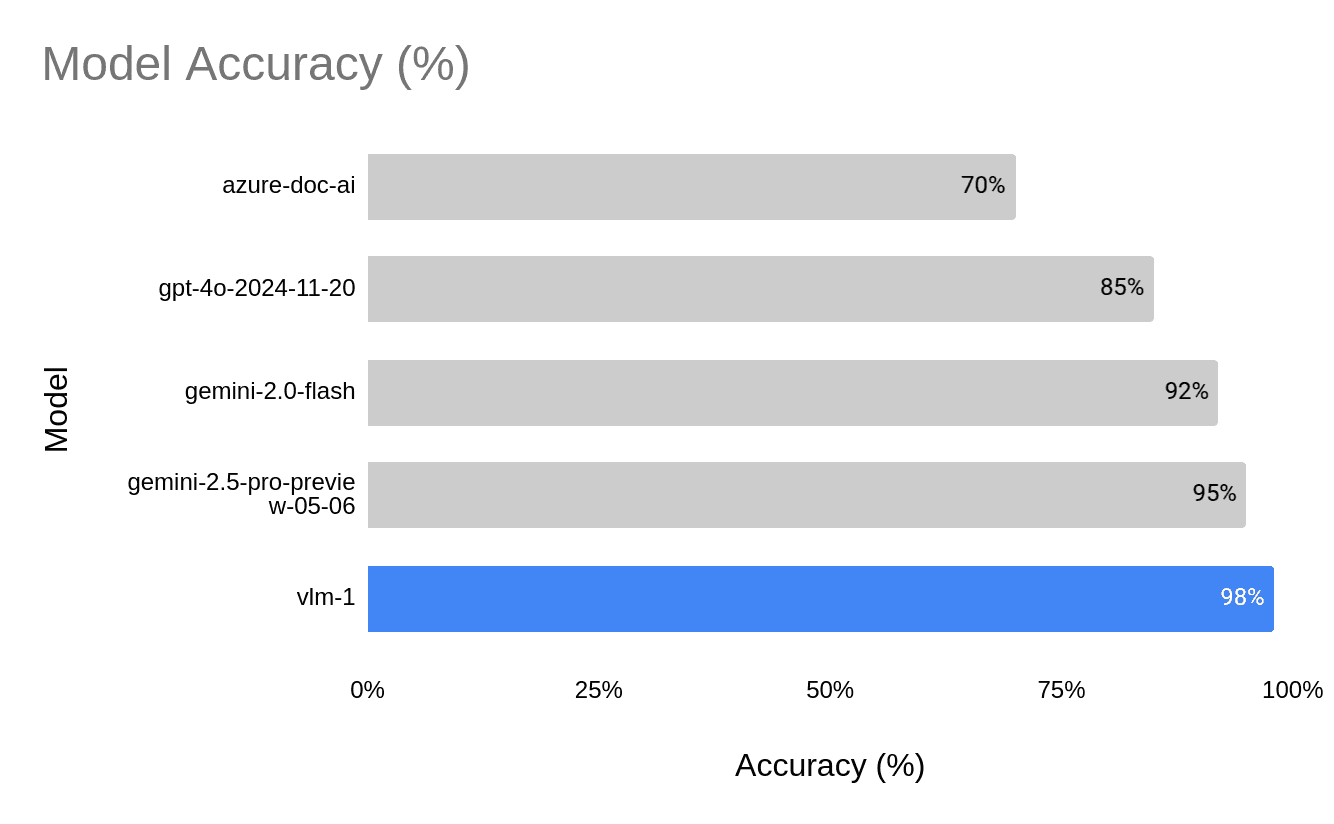
A quick comparison of the accuracy of VLM Run's Document to JSON API against other methods. We observe that VLM Run's accuracy is higher than the other methods showcasing the power of VLM Run's Visual AI approach for challenging edge cases.
Ready to solve your complex document extraction challenges?
Schedule a demo or contact Sales at sales@vlm.run to learn more about how VLM Run can deliver customized Visual AI solutions for your specific needs.


